
活文 知的情報マイニング
「特化型AI」と「生成AI」で
テキストデータを高精度に分析

大量のテキストデータを取り扱う業務でお困りではありませんか?



活文 知的情報マイニングとは
「特化型AI」と「生成AI」による高精度な分析で、大量のテキストデータを扱う業務を効率化
企業には、問い合わせの対応履歴や契約書、報告書といった書類など、膨大なテキストデータが日々蓄積されています。これらのテキストデータは、顧客満足度の向上や新たなビジネス創出につながる可能性を秘めていますが、活用されずに埋もれてしまっていることも少なくありません。
「活文 知的情報マイニング」は、特化型AIと生成AIを活用してテキストデータを高精度に分析し、さまざまな判定や分析などを行う業務の効率化を支援します。
特化型AI
学習済みのAIモデルを、特定の業務に合わせて
チューニングし、その分野に特化して高い精度を発揮

企業固有のノウハウや業界特有の業務に特化
生成AI
大規模な学習データをもとに、幅広い分野について、
対話しながらテキストや画像などを自動生成

さまざまな分野の情報を広く習得
特長
特化型AIによる高精度な文脈理解
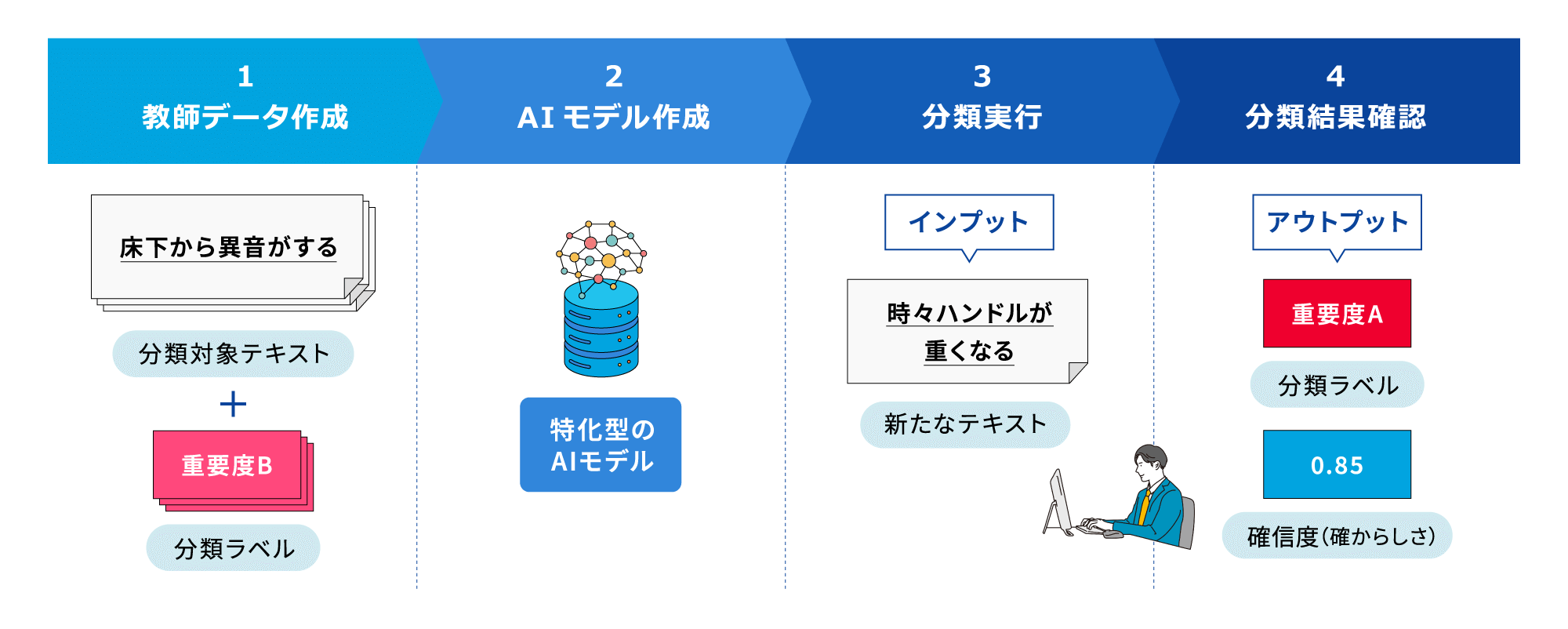
LLMとお客さまにご用意いただく教師データを組み合わせて、特定業務に最適化された特化型のAIモデルを作成。
熟練者の知識に依存せず、高精度な文脈理解を実現します。
業務システムと連携可能なコマンドやAPIを提供
AIモデル作成コマンドや推論APIなど、業務システムとの連携を容易にするコマンドやRESTful APIを提供。
既存の業務フローにスムーズに組み込むことができます。
ユースケース
特化型AI①:クレーム分類
クレームや問い合わせの分類は、経験や業務ルールに基づいて人が判断する必要があります。そのため、機械的に分類することが難しく、次のようなことが課題となっています。
製品サポート業務
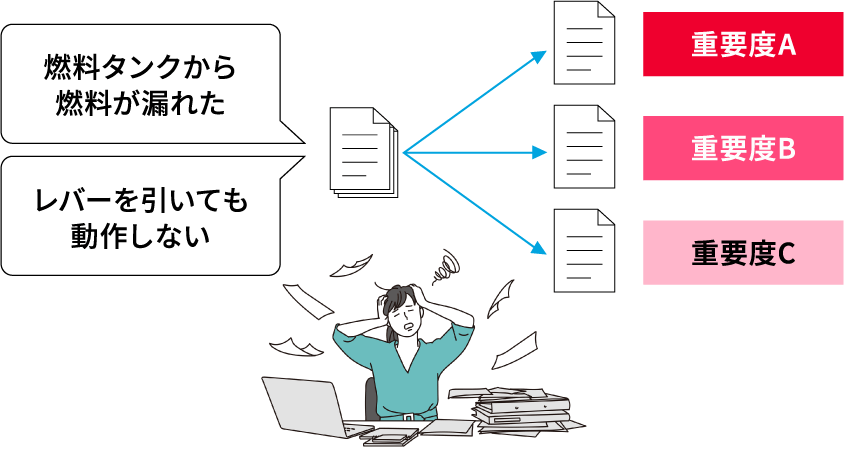
問い合わせ内容の重要度を判定
クレーム分類業務
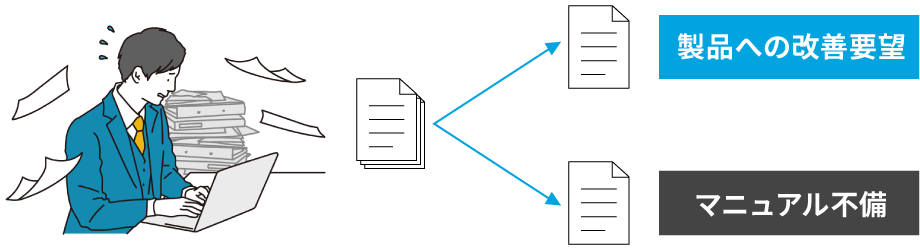
どういう反応のクレーム内容か判定
課題
- 手間と時間がかかる
- 日本語としての内容理解が必要(同じ内容でも書く人によって表現が異なる )
- 業務知識を持つ人材(熟練者)が必要
- 人によって判定結果にばらつきが出る
活文 知的情報マイニングが解決します
クレーム内容や問い合わせ内容などの文章を、決められたカテゴリーに分類する作業を効率化します。
特化型AIで、お客さま固有の内容を含む情報の分類・判定
解決
- 手間のかかる分類作業の効率化によるコスト削減
- 分類精度の均一化による品質の安定化
- 問い合わせ対応のリードタイムを短縮、サービス改善のサイクルのスピードアップ
導入事例
特化型AI②:契約書チェック支援
契約書のチェック業務では、取り引きやプロジェクトを進める際に交わす契約書の内容(仕事の内容、納期、支払い条件、責任の分担、トラブル時の対応など)を一つひとつ確認し、リスクがないか、条件が適切かどうかを確認する必要があり、非常に手間がかかります。契約内容は複雑な場合が多く、細かな条項まで丁寧に確認する必要があり、専門知識が求められます。
契約書チェック作業の課題
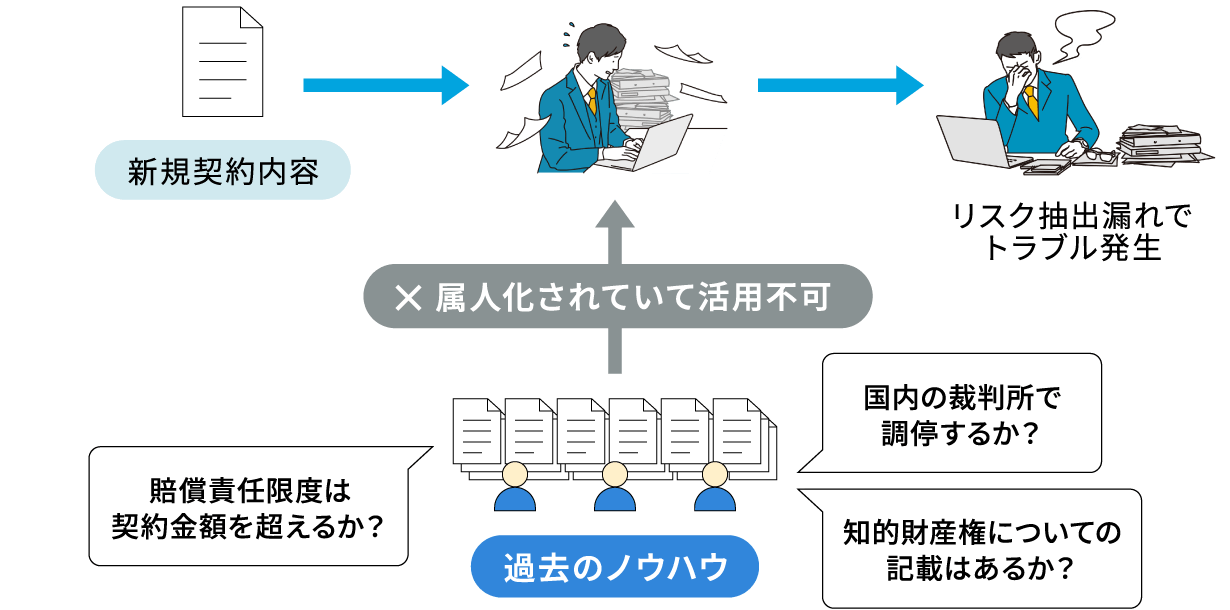
課題
- 知識が属人化されていて、過去のノウハウが活用できていない
- 同じような契約トラブルが何度も発生してしまう
活文 知的情報マイニングが解決します
チェック項目に関連する文章を契約書から抽出。ノウハウが必要な契約書チェック業務を効率化します。
特化型AIで、過去のノウハウを活用して契約リスクがある部分を提示
解決
- 契約リスクがある部分を把握して類似トラブルを防止
- さまざまな観点から契約リスクを迅速に抽出し、担当者は対策の検討に注力できるように
利用イメージ
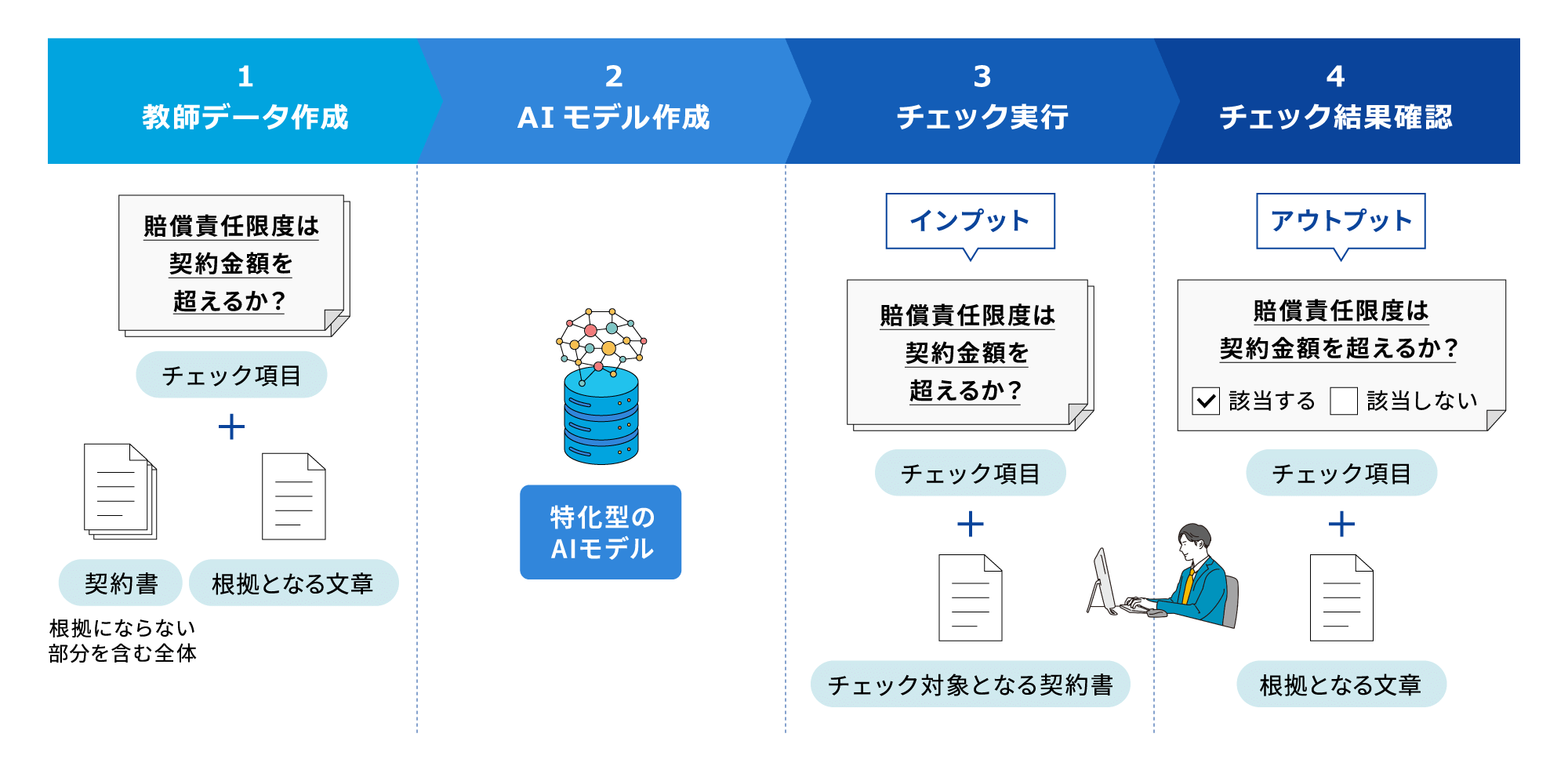
教師データの作成
教師データ作成ツールを利用すると、簡単に教師データを作成することができます。
(1)教師データを作成したいチェック項目を選択します。
(2)チェックした項目に対応する契約内容をマーキングします。

チェック結果の確認
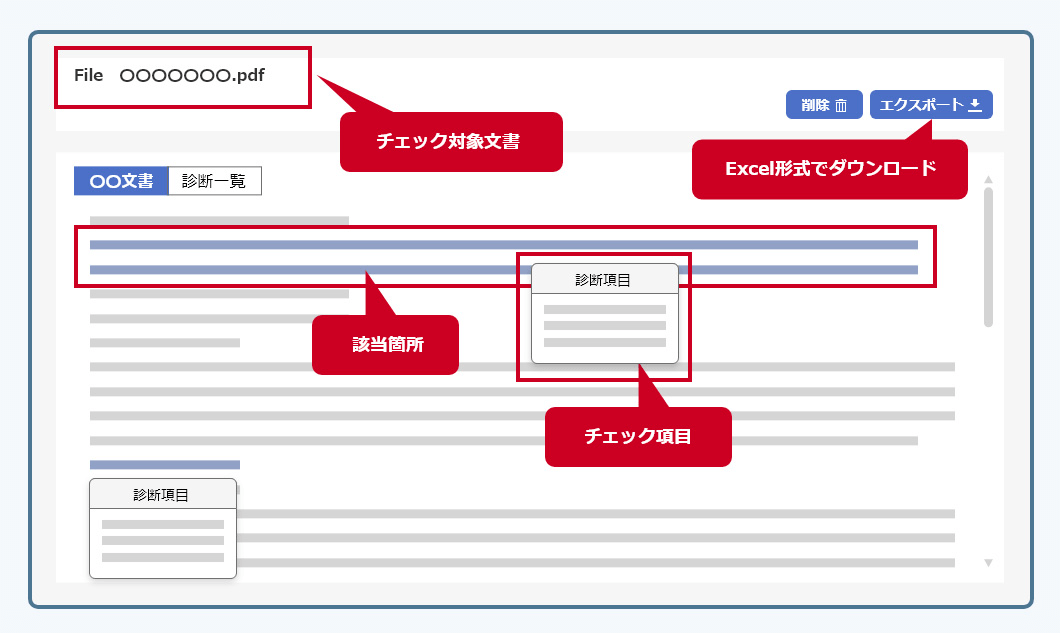
チェック結果を画面で確認できます。契約書全文の中でチェック項目に該当する箇所がハイライト表示され、マウスオーバーでチェック項目の内容が表示されます。チェック結果はExcel形式でダウンロードすることもできます。
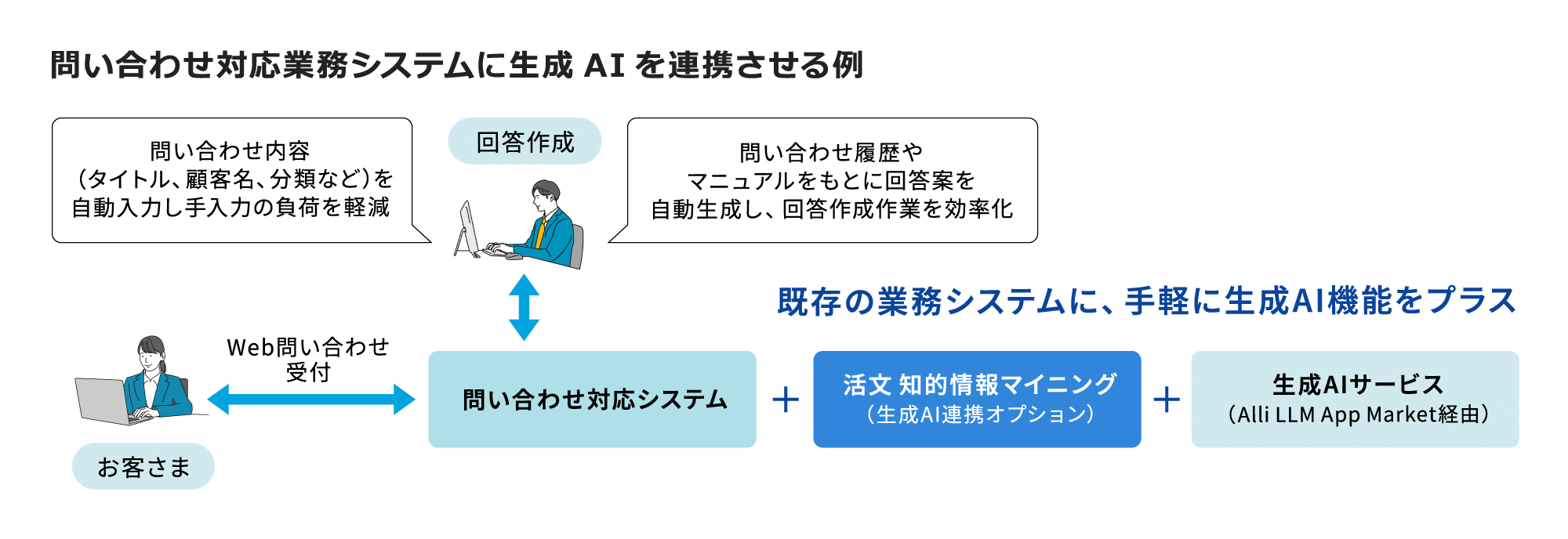
生成AI①:入力フォームへの生成AI適用
例えば、お客さまからの問い合わせ内容や対応状況など、企業では日々、多くの情報をフォームに入力する作業が行われています。これらは業務の基本である一方で、いくつかの課題も抱えています。
これらの課題は、業務の効率やデータ分析に影響を与えるため、改善の余地が大きい領域です。
情報登録作業の課題

課題
- 入力ミスや漏れが発生しやすい
- 定型的で繰り返しの作業が多く、担当者の時間を圧迫する
- 入力者によって表現や粒度が異なり、情報の統一性が保てない
活文 知的情報マイニングが解決します
生成AIがシステムへの情報入力を支援し、人が一から入力する手間を減らします。
お客さまが使用している業務システムと生成AIをつなげるアダプターとして
AIを活用した業務の自動化・効率化を支援
解決
- 現在の業務フローを大きく変えることなく、AIの利便性を取り入れることが可能
- 担当者がゼロから情報を入力する手間を減らし、業務のスピードと正確さを向上
利用イメージ
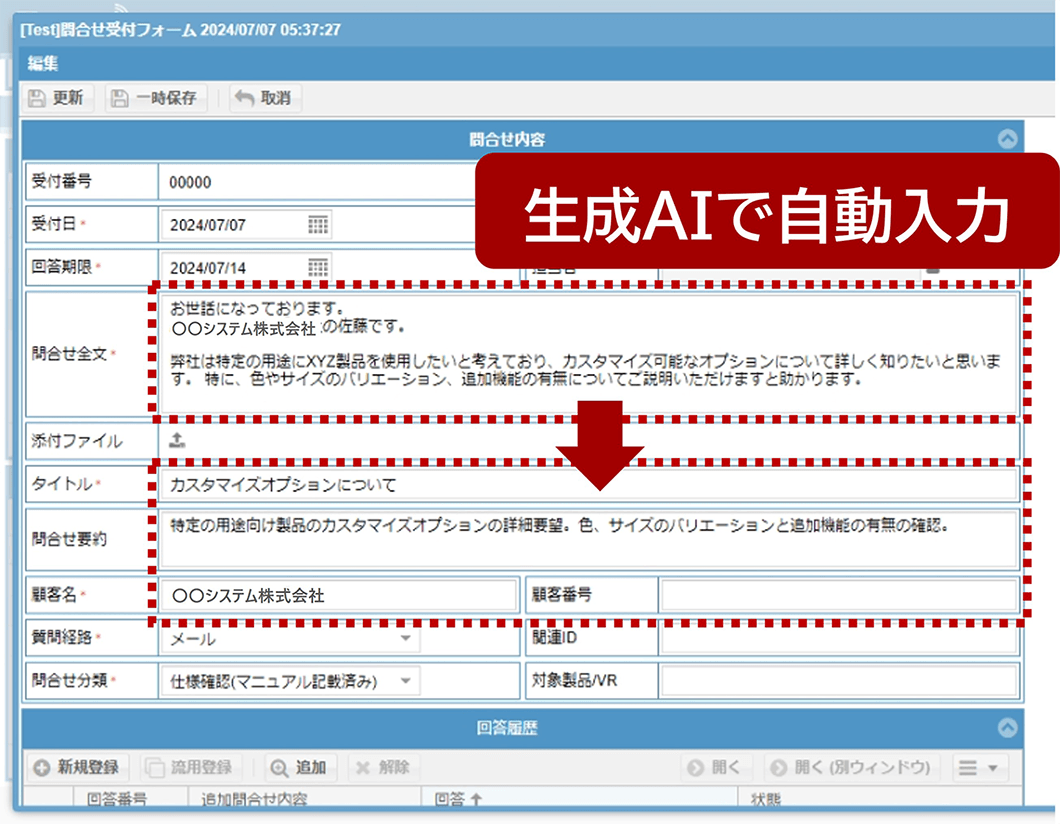
問い合わせ内容から、タイトルや要約文を生成AIで自動入力
生成AIが問い合わせの内容を解析し、タイトルや要約文、顧客名などの管理項目を自動で入力します。担当者が手入力する必要がなくなり、問い合わせへの回答作業を効率化します。
※画面はサンプルです。
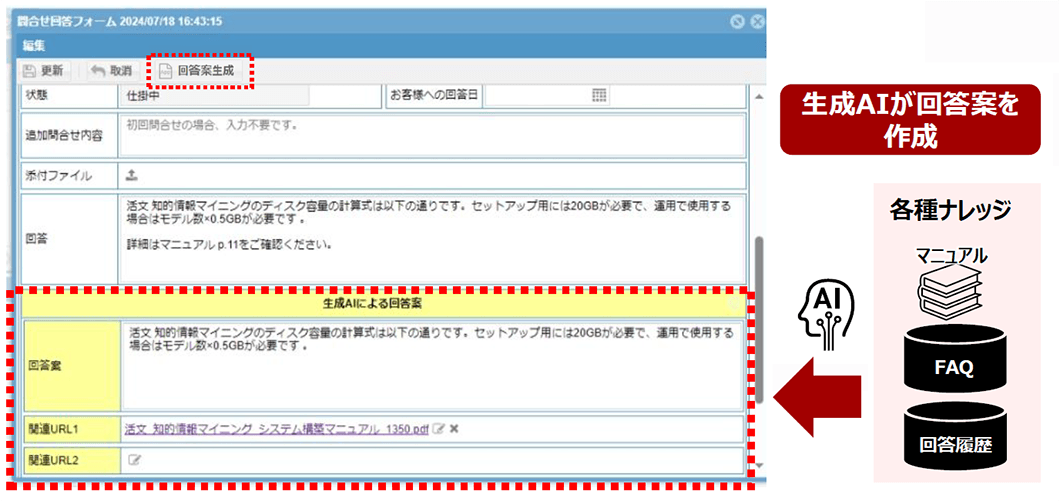
過去の回答履歴やマニュアルから生成AIで回答案を自動生成
AIで最終的な回答案の文法チェックなどの校閲を行うことも可能
過去の問い合わせ回答履歴や、関連するマニュアルなどの各種ナレッジから、回答案を生成AIが自動で作成し、回答作成作業を効率化します。
また、最終的な回答案をAIで校閲をすることで、文法チェックなどの細かいミスをチェックすることも可能です。
※画面はサンプルです。
関連商品


よくあるご質問
-
自然言語処理(NLP:Natural Language Processing)とは?
自然言語処理(NLP)は、人間が日常で使う言葉(日本語や英語などの自然言語)をコンピューターが分析する技術です。テキストデータの意味を解析し、分類などを行います。
人間の言葉は、同じ単語でも文脈によって意味が異なることが多くあります。しかし、近年のビッグデータ処理、AI、ディープラーニングの技術進化に伴い、自然言語で書かれた膨大なテキストデータを実用的に活用するための分類や判定が高精度で可能になりました。
さらに、生成AIやLLMの登場で、従来の解析や分類に加え、文章生成、要約、対話など、より高度な自然言語処理が実現しました。これにより、膨大なテキストデータを活用した業務の効率化や新しいサービスの創出が急速に進んでいます。 -
「特化型AI」とは?
特化型AIは、特定の目的に合わせて調整されたAIのことです。汎用型AIである生成AIは幅広い分野に対応して対話できることに対して、特化型AIは特定の業務や分野に特化して高い精度や効率を発揮します。
「特化型AI」と「生成AI」の違い
特化型AI 生成AI 利用目的 特定業務に特化 幅広い業務で利用可能 導入のしやすさ 要件の整理・データ準備・チューニングが必要 すぐに利用可能 業務への適合性 業務用語・文脈に最適化
社内データを活用し、精度高く応答一般的な回答は可能
業務に特化した内容には弱いセキュリティ・コンプライアンス お客さま専用の環境に構築可能 外部サービス利用時は注意が必要 メンテナンス・運用 継続的な情報のアップデートが必要 アップデートはメーカーが実施
お役立ち情報
ビジネスコラム
AIモデル作成コマンドや推論APIなど、業務システムとの連携を容易にするコマンドやRESTful APIを提供。
既存の業務フローにスムーズに組み込むことができます。



- ※API:Application Programming Interface(プログラムでデータをやり取りするためのインターフェース)
- ※LLM:Large Language Model(大規模自然言語モデル)
- ※記載されている会社名および製品名は、各社の商号、商標、または登録商標です。
活文 製品・ソリューション一覧
価値創出
伝達共有
-
コラボレーション
-
大容量高速ファイル転送
-
ファイル保護
-
電子署名・電子契約
-
メールセキュリティ














